近日语音技术顶会Interspeech 2025发布了录用通知,实验室3篇论文被录用,论文方向涵盖语音情感识别、音频分类、音频深度伪造检测等。Interspeech是由国际语音通信协会(ISCA)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会。实验室被录用的3篇论文介绍如下。
论文1标题:Infant Cry Emotion Recognition Using ImprovedECAPA-TDNN with Multi-scale Feature Fusion and Attention Enhancement
论文1作者:Junyu Zhou, Yanxiong Li*, Haolin Yu
论文1摘要:婴儿哭声情绪识别对于育儿和医学应用至关重要。然而,该领域面临着诸多挑战,例如情绪变化的细微性、噪声干扰以及数据有限等。现有的方法缺乏有效整合多尺度特征和时频关系的能力。本文结合多尺度特征融合和注意力增强,提出一种基于改进ECAPA-TDNN的婴儿哭声情绪识别方法。在公共数据集上的实验结果表明,本文方法获得82.20%的准确率,模型参数量为1.43 MB,计算量为0.32 Giga FLOPs。与基线方法相比,本文方法在准确率和复杂度方面具有优势。
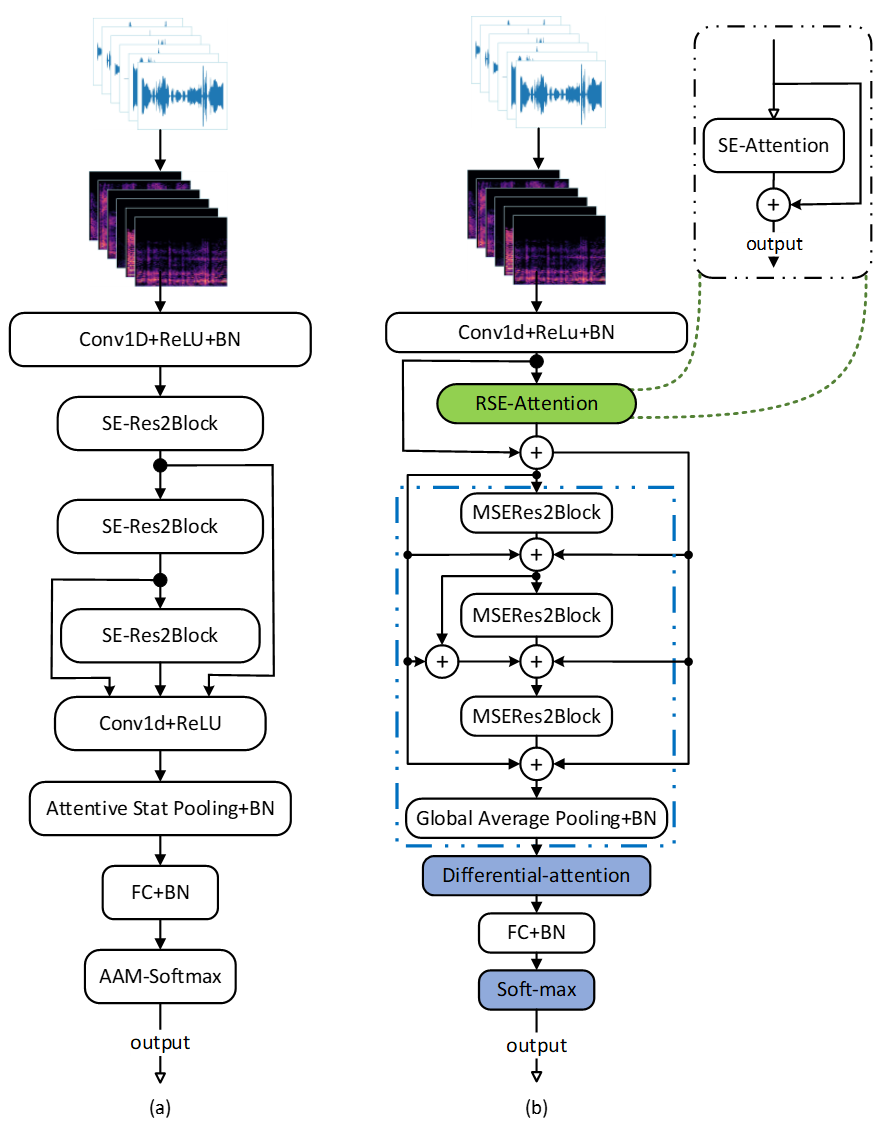
(a)ECAPA-TDNN和(b)改进型ECAPA-TDNN的框架。
论文1资源:https://github.com/kkpretend/IETMA
论文2标题:Fully Few-shot Class-incrementalAudio Classification Using Multi-level Embedding Extractor and Ridge RegressionClassifier
论文2作者:Yongjie Si, Yanxiong Li*, Jiaxin Tan,Qianhua He, Il-Youp Kwak
论文2摘要:在小样本类增量音频分类任务中,每个基类的训练样本都需要足够丰富才能有效训练模型。然而,由于数据稀缺和高收集成本,为基类收集大量训练样本并不容易。本文讨论了一个更现实的问题,即完全小样本类增量音频分类,其中基类和增量类都只有少量训练样本。此外,本文提出一种完全小样本类增量音频分类方法。在该方法中,模型被解耦为一个多级表征提取器和一个岭回归分类器。表征提取器包含音频频谱变换器和融合模块,并在基础环节进行训练,但在增量环节被冻结。分类器在每个增量环节都被更新。在三个公开数据集(LS-100、NSynth-100和FSC-89)的结果表明,本文方法在准确率上超过了以往的方法,在复杂度上也优于大多数方法。
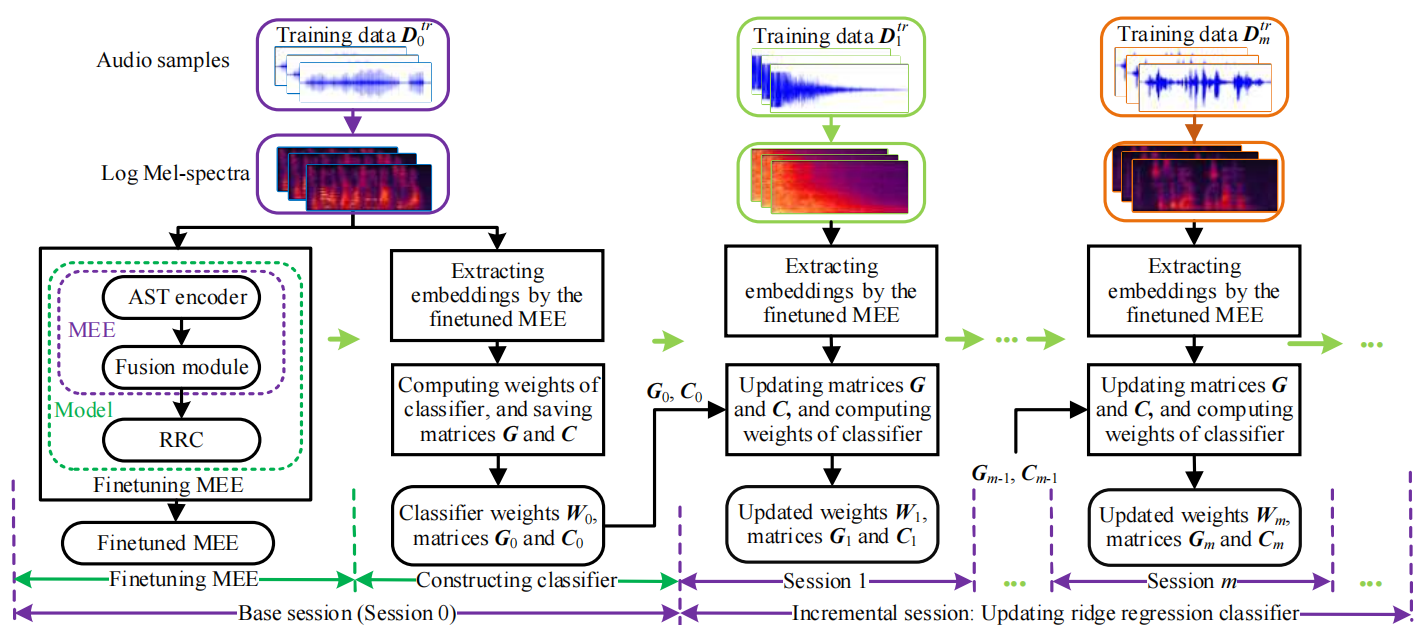
论文方法框图
论文2资源:https://github.com/YongjieSi/MAR
论文3标题:Generalizable Audio Deepfake Detection viaHierarchical Structure Learning and Feature Whitening in Poincaré sphere
论文3作者: Mingru Yang, Yanmei Gu, Qianhua He*, Yanxiong Li, Peirong Zhang, Yongqiang Chen, Zhiming Wang, Huijia Zhu, Jian Liu, Weiqiang Wang
论文3摘要:音频深度伪造检测在应对多样化的现实伪造攻击和领域差异时面临严峻的域泛化挑战。现有方法主要依赖欧几里得距离,难以充分捕捉数据中与攻击类别和领域因素相关的内在层次结构。为了解决这个问题,本文设计一个新颖的框架——Poin-HierNet,用于在庞加莱球面(Poincaré sphere)中构建领域不变的层次化表示。在四个主流开源数据集上评估了本文方法,实验结果表明Poin-HierNet优于当前最先进的方法。
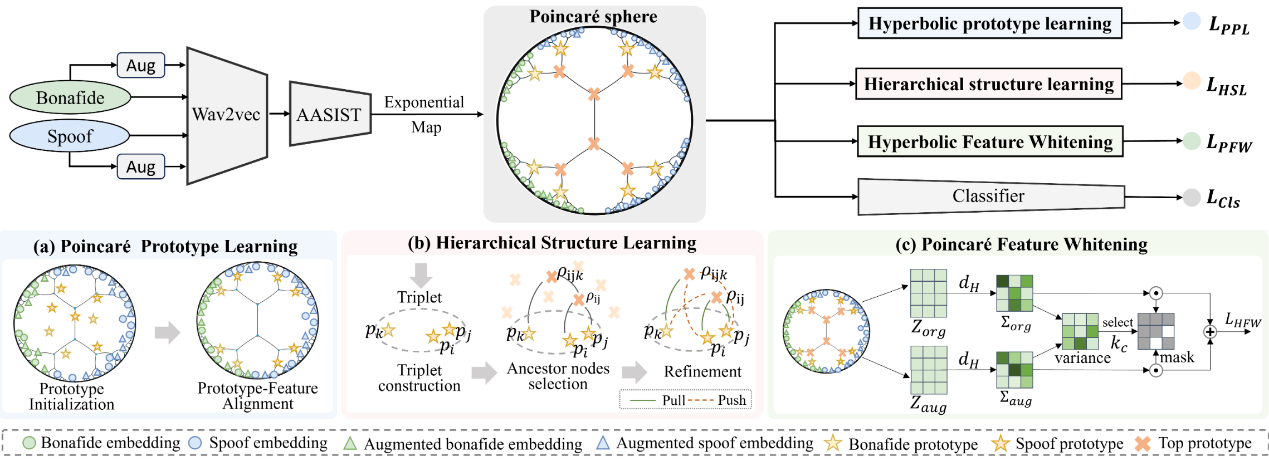
Poin-HierNet 的整体框架。顶部:Poin-HierNet 的训练流程示意图。底部:分别展示了(a)庞加莱原型学习、(b)层次结构学习和(c)庞加莱特征白化三个组件的结构示意图。