2024年9月1日至5日,第25届语音处理国际会议INTERSPEECH在希腊科斯岛举办。INTERSPEECH 2024由国际语音通讯协会(International Speech Communication Association, ISCA)主办,是业界公认的语音处理领域的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。
实验室成员投稿的两篇论文被本次大会录用。论文信息如下:
论文1标题:Fully Few-shot Class-incremental Audio Classification Using Expandable Dual-embedding Extractor
论文1作者:Yongjie Si, Yanxiong Li, Jialong Li, Jiaxin Tan, Qianhua He
论文1摘要:It’sassumed that training data is sufficient in base session of few-shot class-incrementalaudio classification. However, it’s difficult to collect abundant samples formodel training in base session in some practical scenarios due to the datascarcity of some classes. This paper explores a new problem of fully few-shotclass-incremental audio classification with few training samples in allsessions. Moreover, we propose a method using expandable dual-embeddingextractor to solve it. The proposed model consists of an embedding extractorand an expandable classifier. The embedding extractor consists of a pretrainedAudio Spectrogram Transformer (AST) and a finetuned AST. The expandableclassifier consists of prototypes and each prototype represents a class.Experiments are conducted on three datasets (LS-100, NSynth-100 and FSC-89).Results show that our method exceeds seven baseline ones in average accuracywith statistical significance. Code is at: https://github.com/YongjieSi/EDE.
论文方法框图如图1所示。论文详细内容参看论文链接或者论文链接。
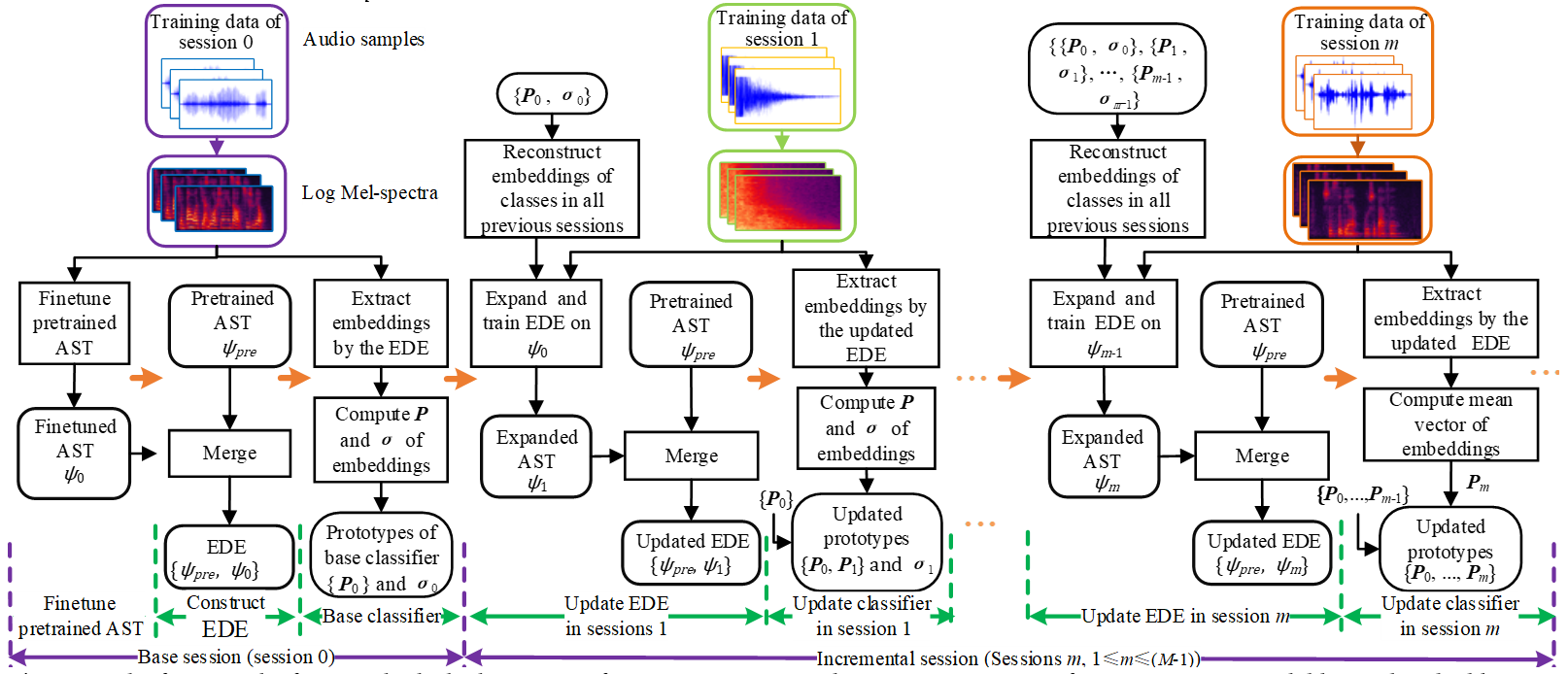
图1 The framework of ourmethod which consists of M sessions. AST: Audio Spectrogram Transformer. EDE:Expandable Dual-embedding Extractor. ψ: parameters of the EDE. P:mean vector of embeddings. σ: covariance of embeddings.
论文2标题:Low-Complexity Acoustic Scene Classification Using Parallel Attention-Convolution Network
论文2作者:Yanxiong Li, Jiaxin Tan, Guoqing Chen, Jialong Li, YongjieSi, Qianhua He
论文2摘要:This work is an improved system that we submitted totask 1 of DCASE2023 challenge. We propose a method of low-complexity acousticscene classification by a parallel attention-convolution network which consistsof four modules, including pre-processing, fusion, global and local contextualinformation extraction. The proposed network is computationally efficient tocapture global and local contextual information from each audio clip. Inaddition, we integrate other techniques into our method, such as knowledgedistillation, data augmentation, and adaptive residual normalization. Whenevaluated on the official dataset of DCASE2023 challenge, our method obtainsthe highest accuracy of 56.10% with parameter number of 5.21 kilo andmultiply-accumulate operations of 1.44 million. It exceeds the top two systemsof DCASE2023 challenge in accuracy and complexity, and obtains state-of-the-artresult. Code is at: https://github.com/Jessytan/Low-complexity-ASC.
论文方法框图如图2所示。论文详细内容参看论文链接或者论文链接。
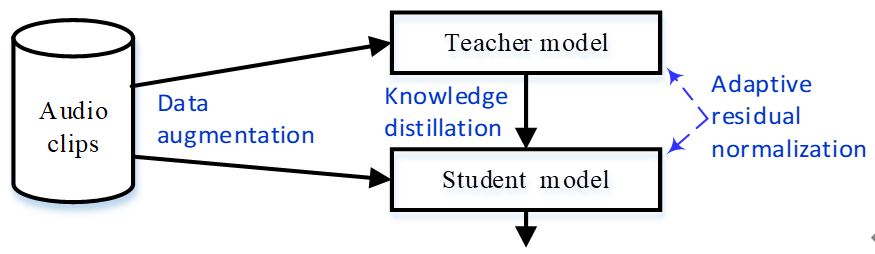
图2 The framework of the proposed method.
司永洁同学在希腊科斯岛参加了此次学术盛会,并宣讲了论文工作(参看图3和图4)。
图3 司永洁同学在大会现场宣讲论文1

图4 司永洁同学在大会现场宣讲论文2