2024年7月12日,实验室研究生司永洁和谭嘉昕在微信公众号语音之家(Speech home)预讲了被语音领域顶会INTERSPEECH 2024录用的论文。第25届INTERSPEECH国际会议将于2024年9月1-5日在希腊的科斯岛举办。INTERSPEECH由国际语音通讯学会(International Speech Communication Association, ISCA)主办,是世界上规模最大、内容最全面的语音处理学术会议。


图1 两位同学线上汇报论文工作
司永洁同学的报告信息如下:
报告题目:Fully Few-shot Class-incremental Audio Classification Using Expandable Dual-embedding Extractor
报告摘要:It's assumed that training data is sufficient in base session of few-shot class-incremental audio classification. However, it's difficult to collect abundant samples for model training in base session in some practical scenarios due to the data scarcity of some classes. This paper explores a new problem offully few-shot class-incremental audio classification with few training samples in all sessions. Moreover, we propose a method using expandable dual-embedding extractor to solve it. The proposed model consists of an embedding extractor and an expandable classifier. The embedding extractor consists of a pretrained Audio Spectrogram Transformer (AST) and a finetuned AST. The expandable classifier consists of prototypes and each prototype represents a class. Experiments are conducted on three datasets (LS-100, NSynth-100 and FSC-89). Results show that our method exceeds seven baseline ones in average accuracy with statistical significance. Code is at: https://github.com/YongjieSi/EDE.
论文方法框图如图2所示。论文详细内容参看论文链接。
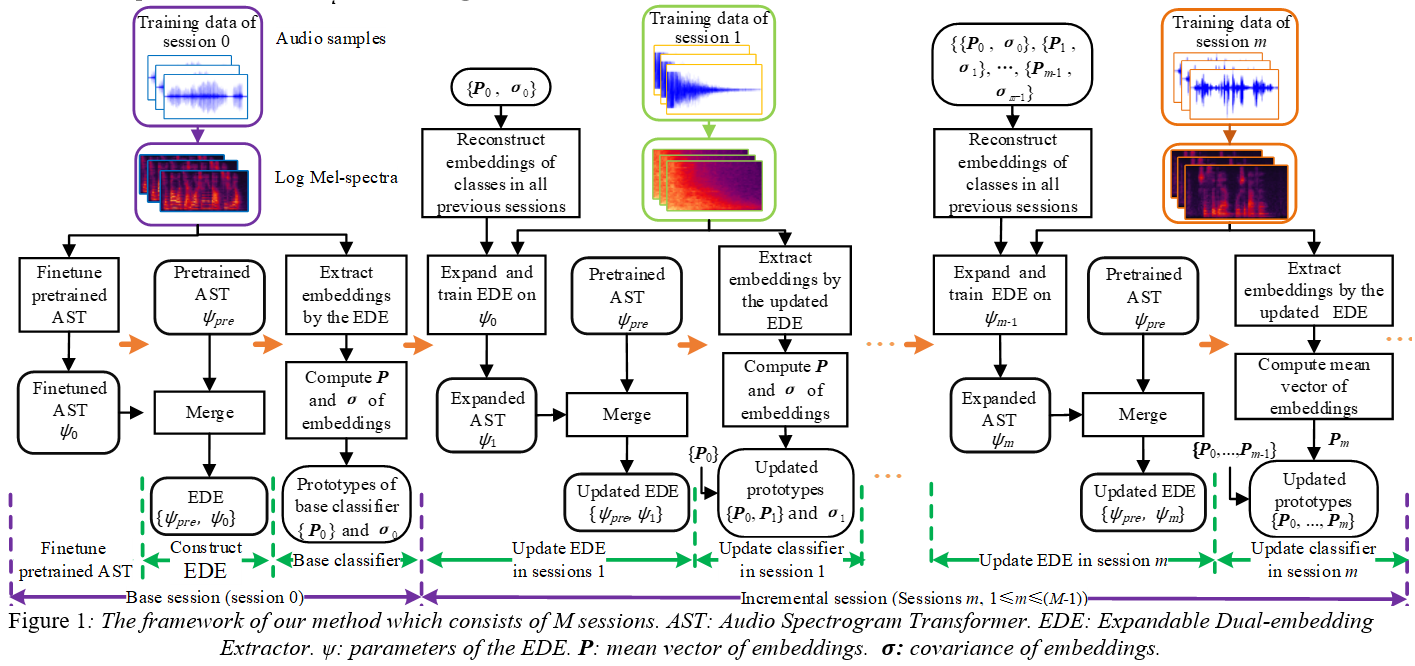
图2 论文方法框图
谭嘉昕同学的报告信息如下:
报告题目:Low-Complexity Acoustic Scene Classification Using Parallel Attention-Convolution Network
报告摘要:This work is an improved system that we submitted to task 1 of DCASE2023 challenge. We propose a method of low-complexity acoustic scene classification by a parallel attention-convolution network which consists of four modules, including pre-processing, fusion, global and local contextual information extraction. The proposed network is computationally efficient to capture globaland local contextual information from each audio clip. In addition, we integrate other techniques into our method, such as knowledge distillation, data augmentation, and adaptive residual normalization. When evaluated on the official dataset of DCASE2023 challenge, our method obtains the highest accuracy of 56.10% with parameter number of 5.21 kilo and multiply-accumulate operations of 1.44 million. It exceeds the top two systems of DCASE2023 challenge in accuracy and complexity, and obtains state-of-the-art result. Codeis at: https://github.com/Jessytan/Low-complexity-ASC.
论文方法框图如图3所示。论文详细内容参看论文链接。
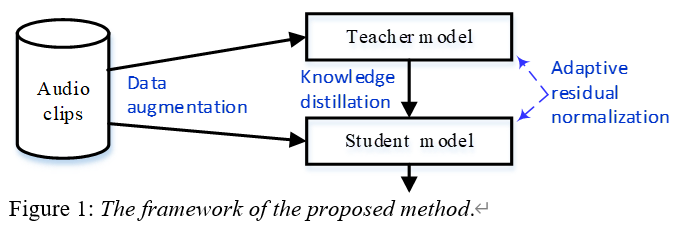
图3 论文方法框图
语音之家预讲会通知详见网址。