2023年8月20日至24日,第24届语音处理国际会议INTERSPEECH在爱尔兰都柏林举办。INTERSPEECH 2023由国际语音通讯协会(International Speech Communication Association, ISCA)主办,是业界公认的语音处理领域的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。
实验室成员投稿的两篇论文被本次大会录用。论文信息如下:
论文1标题:Few-shot Class-incremental Audio Classification Using Stochastic Classifier
论文1作者:Yanxiong Li, Wenchang Cao, Jialong Li, Wei Xie, Qianhua He
论文1摘要:It is generally assumed that number of classes is fixed in current audio classification methods, and the model can recognize pregiven classes only. When new classes emerge, the model needs to be retrained with adequate samples of all classes. If new classes continually emerge, these methods will not work well and even infeasible. In this study, we propose a method for few-shot class-incremental audio classification, which continually recognizes new classes and remember old ones. The proposed model consists of an embedding extractor and a stochastic classifier. The former is trained in base session and frozen in incremental sessions, while the latter is incrementally expanded in all sessions. Two datasets (NS-100 and LS-100) are built by choosing samples from audio corpora of NSynth and LibriSpeech, respectively. Results show that our method exceeds four baseline ones in average accuracy and performance dropping rate.
论文方法框图如图1所示。论文详细内容参看论文链接。
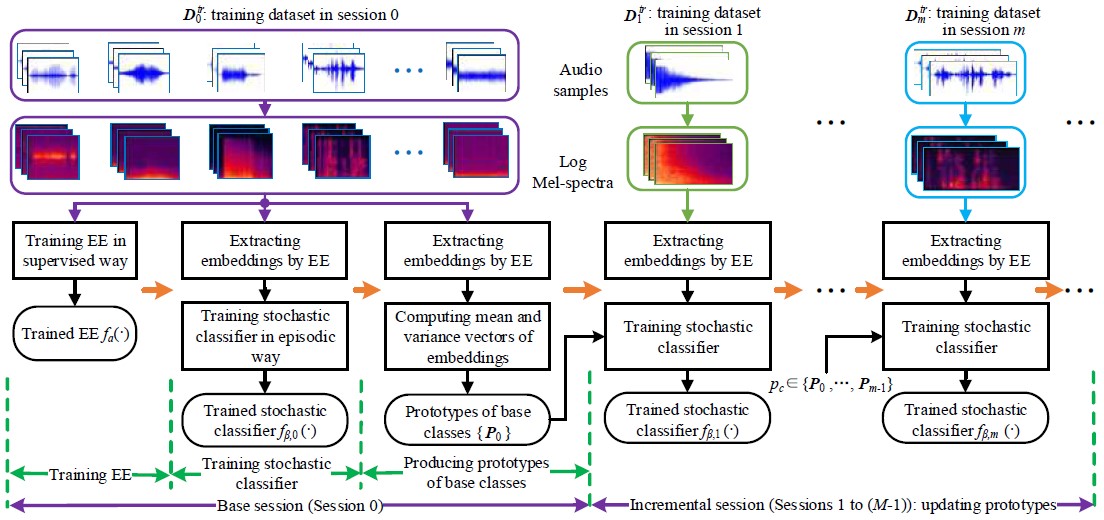
图1 The framework of our method consists of two kinds of sessions: base and incremental sessions. EE: Embedding Extractor.
论文2标题:Few-shot Class-incremental Audio Classification Using Adaptively-refined Prototypes
论文2作者:Wei Xie, Yanxiong Li, Qianhua He, Wenchang Cao, Tuomas Virtanen
论文2摘要:New classes of sounds constantly emerge with a few samples, making it challenging for models to adapt to dynamic acoustic environments. This challenge motivates us to address the new problem of few-shot class-incremental audio classification. This study aims to enable a model to continuously recognize new classes of sounds with a few training samples of new classes while remembering the learned ones. To this end, we propose a method to generate discriminative prototypes and use them to expand the model’s classifier for recognizing sounds of new and learned classes. The model is first trained with a random episodic training strategy, and then its backbone is used to generate the prototypes. A dynamic relation projection module refines the prototypes to enhance their discriminability. Results on two datasets (derived from the corpora of Nsynth and FSD-MIX-CLIPS) show that the proposed method exceeds three state-of-the-art methods in average accuracy and performance dropping rate.
论文方法框图如图2所示。论文详细内容参看论文链接。
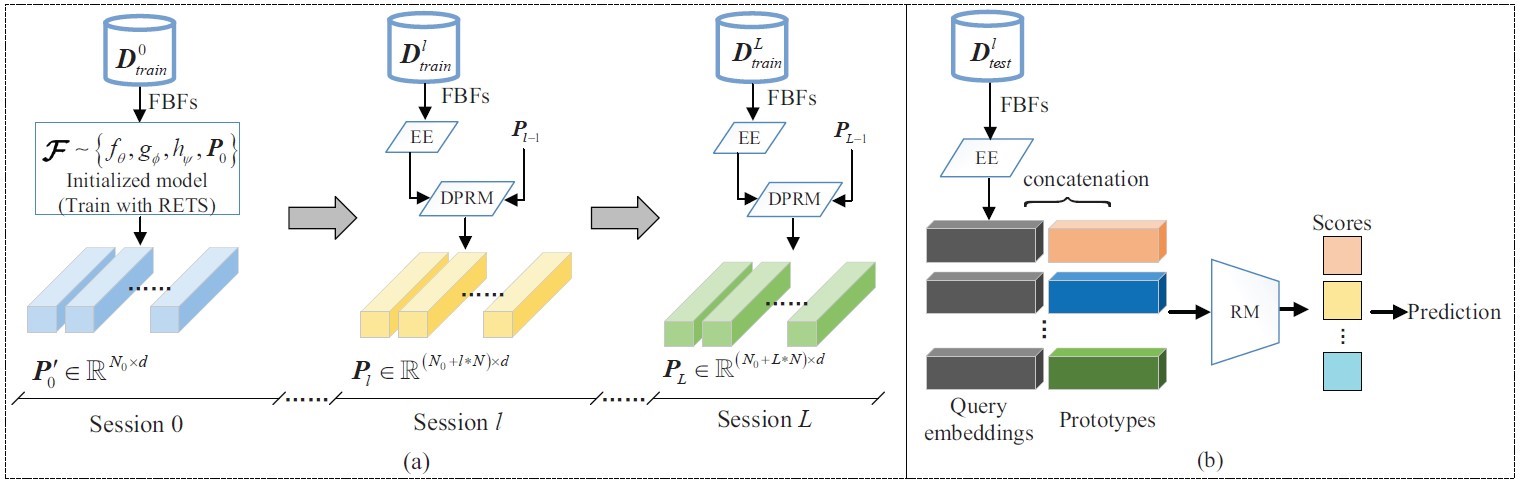
图2 Schematic diagram of the proposed method for FCAC. (a) The process of prototype generation and refinement. (b) Classification of the test samples using the RM and the prototypes.
曹文昌同学在爱尔兰都柏林参加了此次学术盛会,并宣讲了论文工作(参看图3和图4)。

图3 曹文昌同学在大会现场宣讲论文1
图4 曹文昌同学在大会现场宣讲论文2