2023年6月20日,实验室研究生谢伟和曹文昌在微信的语音之家视频号预讲了被语音领域顶会INTERSPEECH 2023录用的论文(图1所示)。第24届INTERSPEECH国际会议将于2023年8月20-24日在爱尔兰都柏林举办。INTERSPEECH由国际语音通讯学会( International Speech Communication Association, ISCA)主办,是世界上规模最大、内容最全面的语音处理学术会议。
图1 两位同学在介绍论文工作
谢伟同学的报告信息如下:
报告主题:基于自适应精炼原型的小样本类别增量音频分类
报告简介:新的声音类别不断出现且一般每类只有几个样本,这使得模型适应动态声学环境具有挑战性。这一挑战促使我们解决小样本类别增量音频分类问题。这项研究的目的是使模型能够在记住旧类声音的同时,基于少量训练样本连续识别新类声音。论文提出了一种区分性原型的生成方法,并使用这些原型扩展模型的分类器,从而识别新类声音和旧类声音。首先,采用随机情景训练策略训练模型;然后,使用模型的主干模块生成原型。我们采用动态关系投影模块对原型进行细化,以增强原型的区分性。在两个数据集(来源于Nsynth和FSD-MIX-CLIPS的语料库)上的实验结果表明,论文方法在平均精度和性能下降率方面超过了三种最先进的方法。
论文方法框图如图2所示。论文详细内容参看论文链接。
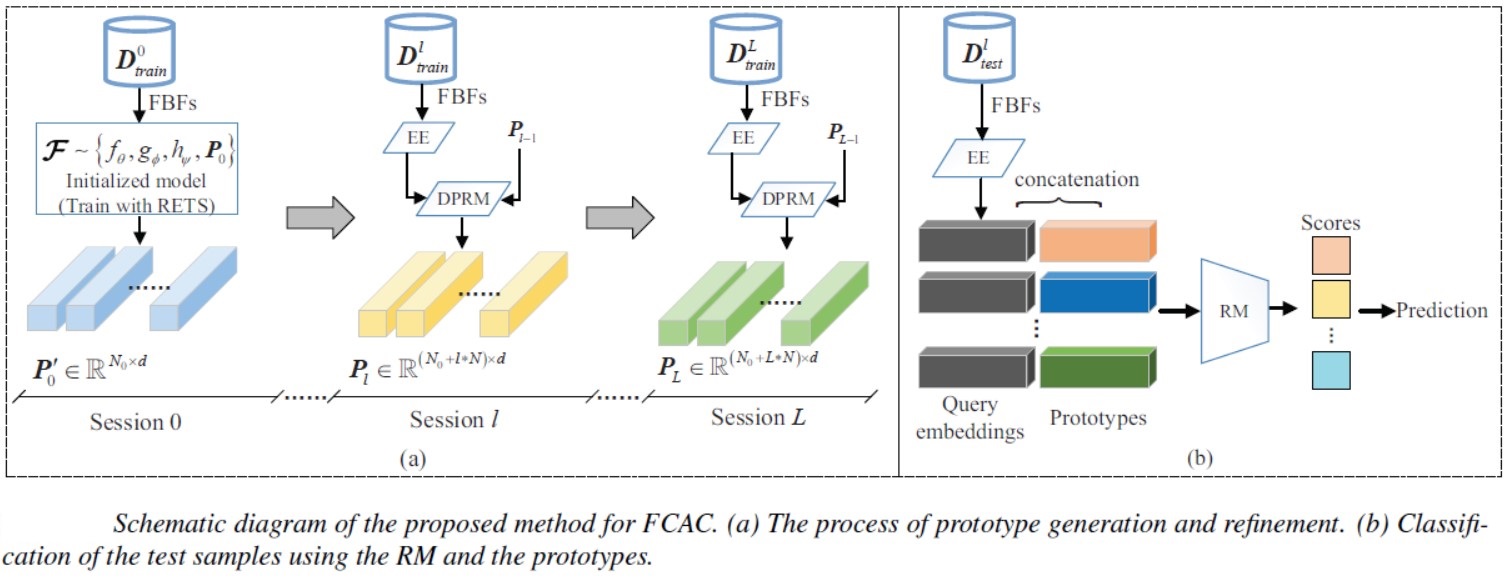
图2 论文方法框图
曹文昌同学的报告信息如下:
报告主题:基于随机分类器的小样本类别增量音频分类
报告简介:在当前的音频分类方法中,通常假设类别数量是固定的,模型只能识别预先给定的类别。当出现新的类别时,需要使用所有类别的足够样本对模型进行再训练。如果新的类别不断出现,目前的方法将不能很好地工作,甚至不能工作。在这项研究中,我们提出了一种小样本类别增量音频分类方法。该方法可以连续识别新类并记住旧类。模型由深度表征提取器和随机分类器组成。前者在基类环节训练并在增量环节冻结,后者在所有环节中都进行动态扩展。从NSynth和LibriSpeech的音频语料库中选择样本,分别构建了两个数据集NS-100和LS-100。实验结果表明,论文方法在平均精度和性能下降率方面超过了四个基线方法。论文方法的代码发布在:https://github.com/vinceasvp/meta-sc。
论文方法框图如图3所示。论文详细内容参看论文链接。报告详细内容参看微信的语音之家视频号。
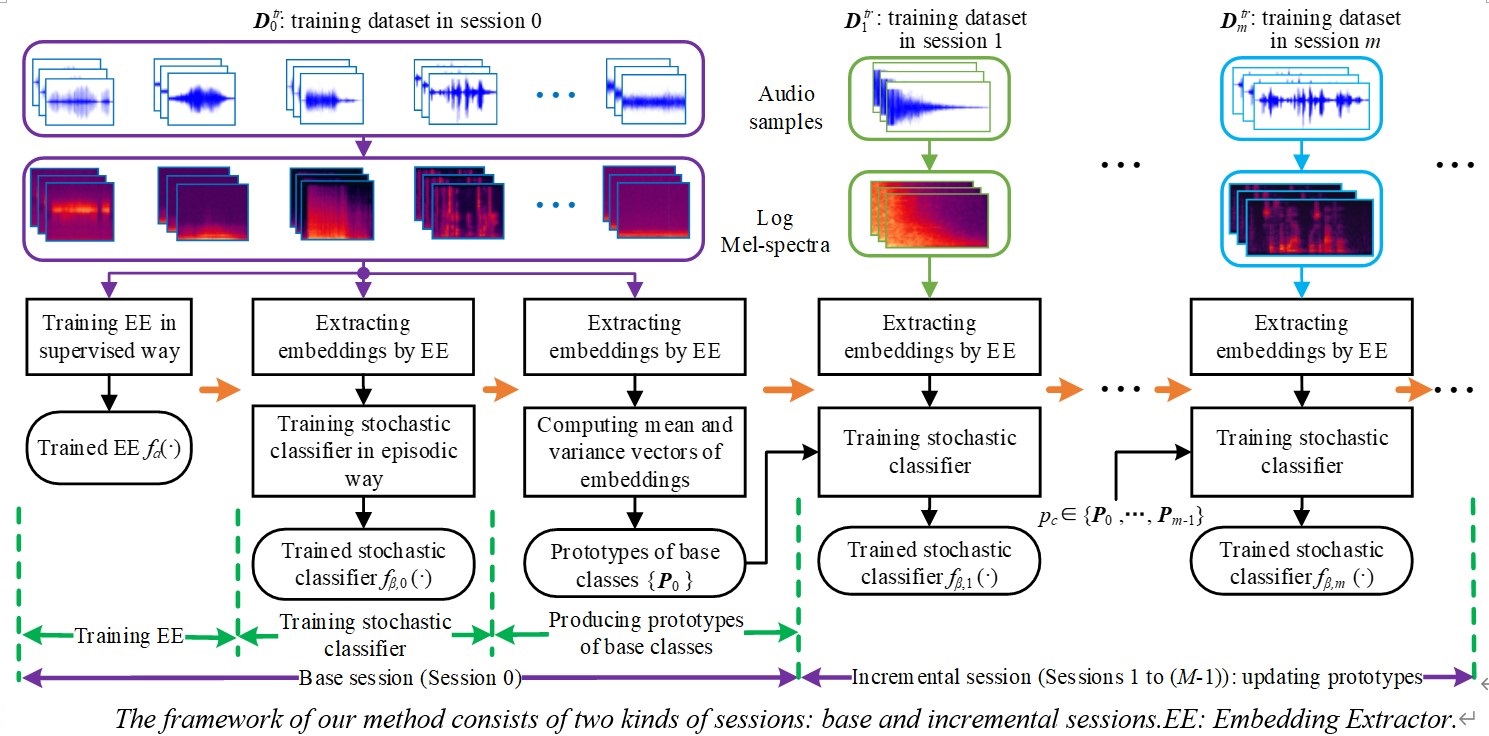
图3 论文方法框图