.
论文1:张聿晗, 李艳雄, 江钟杰, 陈昊. 基于联合学习框架的音频场景聚类[J]. 电子学报, 2021, 49(10): 2041-2047. (EI, CCF A类中文期刊) Yu-han ZHANG, Yan-xiong LI, Zhong-jie JIANG, Hao CHEN. Audio Scene Clustering Based on Joint Learning Framework[J]. Acta Electronica Sinica, 2021, 49(10): 2041-2047. (link)
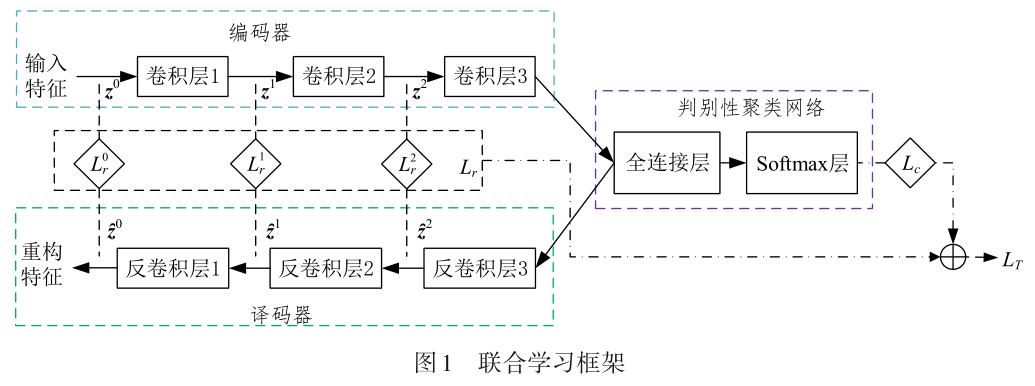
摘 要: 音频场景聚类的任务是将属于相同音频场景的音频样本合并到同一个类中.本文提出一种基于联合学习框架的音频场景聚类方法.该框架由一个卷积自编码网络(Convolution Autoencoder Network, CAN)与一个判别性聚类网络(Discriminative Clustering Network, DCN)组成.CAN包括编码器和译码器,用于提取深度变换特征,DCN用于对输入的深度变换特征进行类别估计从而实现音频场景聚类.采用DCASE-2017和LITIS-Rouen数据集作为实验数据,比较不同特征与聚类方法的性能.实验结果表明:采用归一化互信息和聚类精度作为评价指标时,基于联合学习框架提取的深度变换特征优于其他特征,本文方法优于其他方法.本文方法所需要付出的代价是需要较大的计算复杂度. |
论文2:Yanxiong Li, Yuhan Zhang, Xianku Li, Mingle Liu, Wucheng Wang, and Jichen Yang. Acoustic event diarization in TV/movie audios using deep embedding and integer linear programming. Multimedia Tools and Applications 78, no. 23 (2019): 33999-34025. (SCI, JCR Q2) (link)
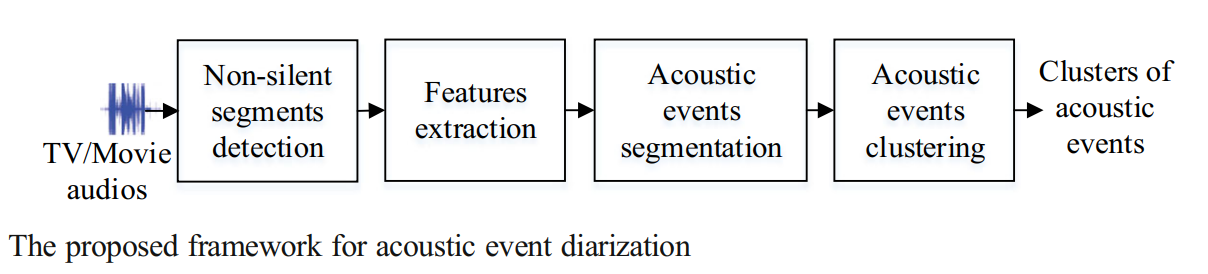
Abstract In this study, we propose a method for acoustic event diarization based on a feature of deep embedding and a clustering algorithm of integer linear programming. The deep embedding learned by deep auto-encoder network is used to represent the properties of different classes of acoustic events, and then the integer linear programming is adopted for merging audio segments belonging to the same class of acoustic events. Four kinds of TV/movie audios (21.5 h in total) are used as experimental data, including Sport, Situation comedy, Award ceremony, and Action movie. We compare the deep embedding with state-of-the-art features. Further, the clustering algorithm of integer linear programming is compared with other clustering algorithms adopted in previous works. Finally, the proposed method is compared to both supervised and unsupervised methods on four kinds of TV/movie audios. The results show that the proposed method is superior to other unsupervised methods based on agglomerative information bottleneck, Bayesian information criterion and spectral clustering, and is little inferior to the supervised method based on deep neural network in terms of acoustic event error. |
作者简介:张聿晗 男,实验室2017级硕士研究生,主要研究方向为语音及音频信号处理、机器学习. 目前,张聿晗已经顺利毕业,并入职科大讯飞从事研发工作。

|